Apophenia is an open statistical library for working with data sets and statistical models. It provides functions on the same level as those of the typical stats package (such as OLS, Probit, or singular value decomposition) but gives the user more flexibility to be creative in model-building. The core functions are written in C, but experience has shown them to be easy to bind to in Python/Julia/Perl/Ruby/&c.
It is written to scale well, to comfortably work with gigabyte data sets, million-step simulations, or computationally-intensive agent-based models.
The goods
The library has been growing and improving since 2005, and has been downloaded well over 1e4 times. To date, it has over two hundred functions and macros to facilitate statistical computing, such as:
- OLS and family, discrete choice models like Probit and Logit, kernel density estimators, and other common models.
- Functions for transforming models (like Normal
 truncated Normal) and combining models (produce the cross-product of that truncated Normal with three others, or use Bayesian updating to combine that cross-product prior with an OLS likelihood to produce a posterior distribution over the OLS parameters).
truncated Normal) and combining models (produce the cross-product of that truncated Normal with three others, or use Bayesian updating to combine that cross-product prior with an OLS likelihood to produce a posterior distribution over the OLS parameters).
- Database querying and maintenance utilities.
- Data manipulation tools for splitting, stacking, sorting, and otherwise shunting data sets.
- Moments, percentiles, and other basic stats utilities.
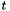 -tests,
-tests,  -tests, et cetera.
-tests, et cetera. - Several optimization methods available for your own new models.
- It does not re-implement basic matrix operations or build yet another database engine. Instead, it builds upon the excellent GNU Scientific and SQLite libraries. MySQL/mariaDB is also supported.
For the full list of macros, functions, and prebuilt models, check the index.
Download Apophenia here.
Or, see the Setting up page for detailed setup instructions, including how to use your package manager to install the Debian or Homebrew package.
The documentation
To start off, have a look at this Gentle Introduction to the library.
The outline gives a more detailed narrative.
The index lists every function in the library, with detailed reference information. Notice that the header to every page has a link to the outline and the index.
To really go in depth, download or pick up a copy of Modeling with Data, which discusses general methods for doing statistics in C with the GSL and SQLite, as well as Apophenia itself. A Useful Algebraic System of Statistical Models (PDF) discusses some of the theoretical structures underlying the library.
There is a wiki with some convenience functions, tips, and so on.
Notable features Much of what Apophenia does can be done in any typical statistics package. The apop_data structure is much like an R data frame, for example, and there is nothing special about being able to invert a matrix or take the product of two matrices with a single function call (apop_matrix_inverse and apop_dot, respectively). Even more advanced features like Loess smoothing (apop_loess) and the Fisher Exact Test (apop_test_fisher_exact) are not especially Apophenia-specific. But here are some things that are noteworthy.
- It's a C library! You can build applications using Apophenia for the data-processing back-end of your program, and not worry about the overhead associated with scripting languages. For example, it is currently used in production for certain aspects of processing for the U.S. Census Bureau's American Community Survey. And the numeric routines in your favorite scripting language typically have a back-end in plain C; perhaps Apophenia can facilitate writing your next one.
- The apop_model object allows for consistent treatment of distributions, regressions, simulations, machine learning models, and who knows what other sorts of models you can dream up. By transforming and combining existing models, it is easy to build complex models from simple sub-models.
- For example, the apop_update function does Bayesian updating on any two well-formed models. If they are on the table of conjugates, that is correctly handled, and if they are not, an appropriate variant of MCMC produces an empirical distribution. The output is yet another model, from which you can make random draws, or which you can use as a prior for another round of Bayesian updating. Outside of Bayesian updating, the apop_model_metropolis function is good for approximating other complex models.
- The maximum likelihood system combines several subsystems into one form: it will do a few flavors of conjugate gradient search, Nelder-Mead Simplex, Newton's Method, or Simulated Annealing. You pick the method by a setting attached to your model. If you want to use a method that requires derivatives and you don't have a closed-form derivative, the ML subsystem will estimate a numerical gradient for you. If you would like to do EM-style maximization (all but the first parameter are fixed, that parameter is optimized, then all but the second parameter are fixed, that parameter is optimized, ..., looping through dimensions until the change in objective across cycles is less than
eps), add a settings group specifying the tolerance at which the cycle should stop: Apop_settings_add_group(your_model, apop_mle, .dim_cycle_tolerance=eps).
- The Iterative Proportional Fitting algorithm, apop_rake, is best-in-breed, designed to handle large, sparse matrices.
Contribute!
- Develop a new model object.
- Contribute your favorite statistical routine.
- Package Apophenia into an RPM, portage, cygwin package.
- Report bugs or suggest features.
- Write bindings for your preferred language. For example, here are a Perl wrapper and early versions of a Julia wrapper and an R wrapper which you could expand upon.
If you're interested, write to the maintainer (Ben Klemens), or join the GitHub project.

